
Lucene
Presentazione di un applicativo IR.
Un'applicazione di ricerca ed indicizzazione esegue tutte o alcune delle seguenti operazioni:
- Acquisisci contenuti grezzi: Il primo passo di qualsiasi applicazione di ricerca è quello di raccogliere i contenuti di destinazione su cui deve essere condotta l'applicazione di ricerca
- Costruisci il documento: Il passaggio successivo consiste nel creare i documenti dal contenuto non elaborato, che l'applicazione di ricerca può comprendere e interpretare facilmente.
- Analizza il documento: Prima che inizi il processo di indicizzazione, il documento deve essere analizzato su quale parte del testo è un candidato da indicizzare. Questo processo è dove viene analizzato il documento.
- Indicizzazione del documento: Una volta creati e analizzati i documenti, il passaggio successivo è indicizzarli in modo che questo documento possa essere recuperato in base a determinate chiavi anziché all'intero contenuto del documento. Il processo di indicizzazione è simile agli indici alla fine di un libro in cui vengono visualizzate parole comuni con i loro numeri di pagina in modo che queste parole possano essere rintracciate rapidamente invece di cercare nel libro completo.
- Interfaccia utente per la ricerca: Una volta pronto un database di indici, l'applicazione può effettuare qualsiasi ricerca. Per facilitare un utente a effettuare una ricerca, l'applicazione deve fornire a un utente una media o un'interfaccia utente in cui un utente può inserire il testo e avviare il processo di ricerca.
- Creazione di una Query: Una volta che un utente ha effettuato una richiesta di ricerca di un testo, l'applicazione deve preparare un oggetto Query per richiedere al database degli indici le informazioni pertinenti.
- Esecuzione della Query: Utilizzando un oggetto Query, viene quindi verificato il database dell'indice per ottenere i dettagli pertinenti e i documenti che contengono l'informazione.
- Esposizione dei risultati: Una volta ricevuto il risultato, l'applicazione deve decidere come mostrare i risultati all'utente mediante l'interfaccia utente. Quante informazioni devono essere mostrate a prima vista e così via.
Apache lucene e' un framework per creare applicativi di ricerca ed indicizzazione.
Sito ufficiale: https://lucene.apache.org/
le caratteristiche principali sono:
- Indicizzazione strutturata per campi
- Diversi strumenti di preprocessing per diverse lingue
- Differenti tipologie di Query: phrase queries, wildcard queries, proximity,queries, range queries, etc...
- Ricerca per campi singoli
- Ricerca per campi multipli (i risultati vengono uniti)
L’indice inverso ha una rappresentazione strutturata in:
- una sequenza di documenti
- ogni documento e' composto da una sequenza di campi
- ogni campo e' una sequenza termini
I campi sono indipendenti. La stessa stringa che occorre in due campi differenti rappresenta due termini diversi
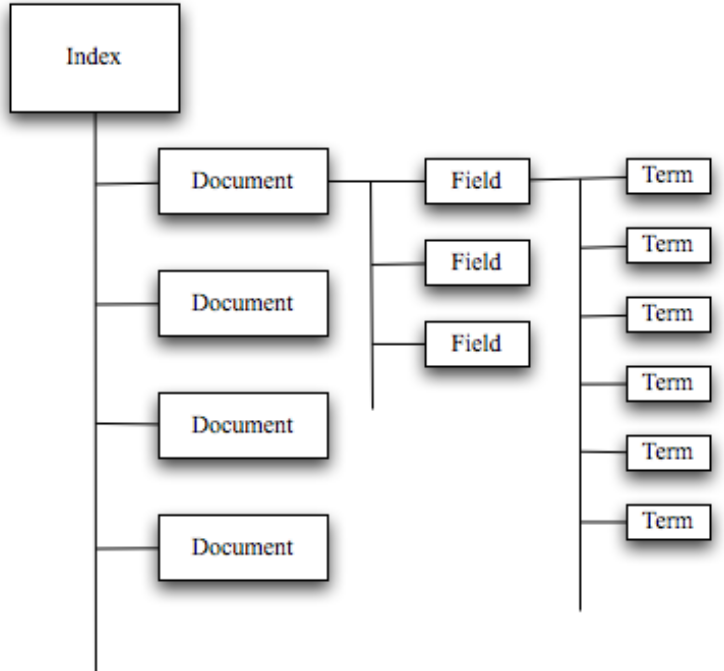
L’indice e' composto dalle seguenti parti:
- Field names: Contiene i nomi dei campi di un documento.
- Stored Field values: per ciascun documento indicizzato, all’interno di questo campo viene memorizzata una coppia attributo-valore, dove gli attributi corrispondono ai nomi dei campi.
- Term dictionary: rappresenta il dizionario ricavato dal documento processato. Per ciascun termine nel dizionario viene memorizzato anche il numero complessivo di documenti in cui compare il termine, e i puntatori a Term Frequency data e Term Proximity data, del termine.
- Term Frequency data: Per ciascun termine questa struttura contiene le informazioni riguardo ai documenti che contengono il termine, e la frequenza con cui compare nel documento.
- Term Proximity data: Per ciascun termine questa struttura permette di rappresentare le posizioni all’interno del documento in cui il termine compare.
- Normalization factors: Per ciascun campo in un documento vengono memorizzati dei fattori di normalizzazione.
- Term Vectors: Per ciascun documento e’ possibilie memorizzare un vettore che contiene i termini contenuti nel documento con la relativa frequenza.
Tipi di query e sintassi :
- Query Generica: pantera rosa
- Query a blocchi:"pantera rosa"
- Operatory booleani: "pantera rosa" AND return oppure "pantera rosa" +return
- Query per campi: title:"pantera rosa"
- Wildcard: pant?ra oppure panter*
- Fuzzy: panther~ oppure panther~0.8 (esempio: se in google cerchi "Pote italiane" ti risponde "Forse cercavi Poste Italiane" e ti da quel tipo di risultato)
- Prossimita': "panther rosa"~10 documento che contiene le due parole a meno di 10 termini di distanza
- Pesature: pantera rosa^4 (permette di dare un peso ad una parola rispetto ad un altra)
- Range: mod_date:[20070101 TO 20071001]
- Gruppi: title:(+return +"pantera rosa")
Il modello di ranking si basa su la funzione di peso tf-idf (term frequency–inverse document frequency) che è una funzione utilizzata in information retrieval per misurare l'importanza di un termine rispetto ad un documento o ad una collezione di documenti. Tale funzione aumenta proporzionalmente al numero di volte che il termine è contenuto nel documento, ma cresce in maniera inversamente proporzionale con la frequenza del termine nella collezione. L'idea alla base di questo comportamento è di dare più importanza ai termini che compaiono nel documento, ma che in generale sono poco frequenti. https://it.wikipedia.org/wiki/Tf-idf
- https://en.wikipedia.org/wiki/Vector_space_model Vector space model
- https://en.wikipedia.org/wiki/Okapi_BM25 Best Matching 25 basato sun "probabilistic retrieval framework"
La funzione di similitudine tra un documento e la query e' la seguente:

Package principali API Lucene (Application Programming Interface)
- org.apache.lucene.document: contiene le classi per la rappresentazione del documento per l'indicizzazione e la ricerca.
- org.apache.lucene.analysis: contiene le classi per la gestione delle funzioni di pre-processing per l’indicizzazione del documento.
- org.apache.lucene.search: contiene le classi per la gestione delle funzioni che implementano differenti modelli di ricerca.
- org.apache.lucene.index: contiene le classi per la creazione/modifica e accesso dell’indice.
- org.apache.lucene.store: contiene le classi per la scrittura e lettura (accesso binanrio I/O) dell’indice su disco.
Schema procedurale per l’indicizzazione:
- Definire un modulo di pre-processamento attraverso la classe Analyzer.
- Creare un IndexWriter ,in un path definito di archivio, configurarlo e inserire un riferimento all'Analyzer.
- Per ciascun documento nella collezione: creare un oggetto Document e aggiungere al documento i vari campi di tipo Field.
- Aggiungere all’IndexWriter i vari Document tramite il metodo addDocument().
Parte 1:
Analyzer analyzer = new StandardAnalyzer();
Path indexPath = Files.createTempDirectory("tempIndex");
Directory directory = FSDirectory.open(indexPath)
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter iwriter = new IndexWriter(directory, config);
Document doc = new Document();
String text = "This is the text to be indexed.";
doc.add(new Field("fieldname", text, TextField.TYPE_STORED));
iwriter.addDocument(doc);
iwriter.close();Schema procedurale per la ricerca:
- Definire lo stesso modulo di pre-processamento usato durante l’indicizzazione attraverso la classe Analyzer.
- Aprire l’indice dei documenti attraverso la classe IndexSearcher e riferimento alla path di archiviazione dell'indice.
- Definire il parser della query QueryParser.
- Definire il modello di Query che si vuole adottare (generica, a blocchi,wildcard).
- Ricercare i documenti secondo il modello scelto attraverso la classe IndexSearcher.
- Presentare i risultati.
Parte 2:
// Now search the index:
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher isearcher = new IndexSearcher(ireader);
// Parse a simple query that searches for "text":
QueryParser parser = new QueryParser("fieldname", analyzer);
Query query = parser.parse("text");
ScoreDoc[] hits = isearcher.search(query, 10).scoreDocs;
assertEquals(1, hits.length);
// Iterate through the results:
for (int i = 0; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
assertEquals("This is the text to be indexed.", hitDoc.get("fieldname"));
}
ireader.close();
directory.close();
IOUtils.rm(indexPath)Tool di analisi
il pacchetto che della libreria contiene un tool che consente l'analis degli indici creati nel path:
- /path/to/lucene-x.x.x/luke/luke.sh
